Super Dependence In Modern Software


A primer on transitive dependencies in open source software and how it results in super dependence.
Software has argulably become the fundamental basis for infrastructure across all industries today. Not only do we rely on software to power the technology behind our everyday experiences in personal life and work — we rely on software to operate critical physical systems like power plants, transportation networks, manufacturing lines, and financial systems.
# Software has Eaten the World, and Open Source has Eaten Software
The pervasiveness of software can be attributed to the rise of open source. Open source has become the de facto standard for building blocks of modern software across every indstry and use case, and has been adopted at scale over the last decade and to form the backbone of our global technological foundations today. From indie projects to critical infrastructure, all kinds of software today is predominantly comprised of open source.
The power of open source lies in community - because it allows developers all over the world to collaborate and share code with each other, which enables them to build and improve on products faster than ever, while using the collective knowledge and experience of the community behind it. The improvement in open source frameworks and libraries across every vertical in software has fostered unprecedented collaboration, innovation, and advancement not just in the developer community, but has also influenced advances other disciplines such as science, law and policy.
Putting this in context today, the number of open source dependencies being downloaded and integrated into software grew by an estimated average of 33% across all the monitored ecosystems in 2022 (cite)
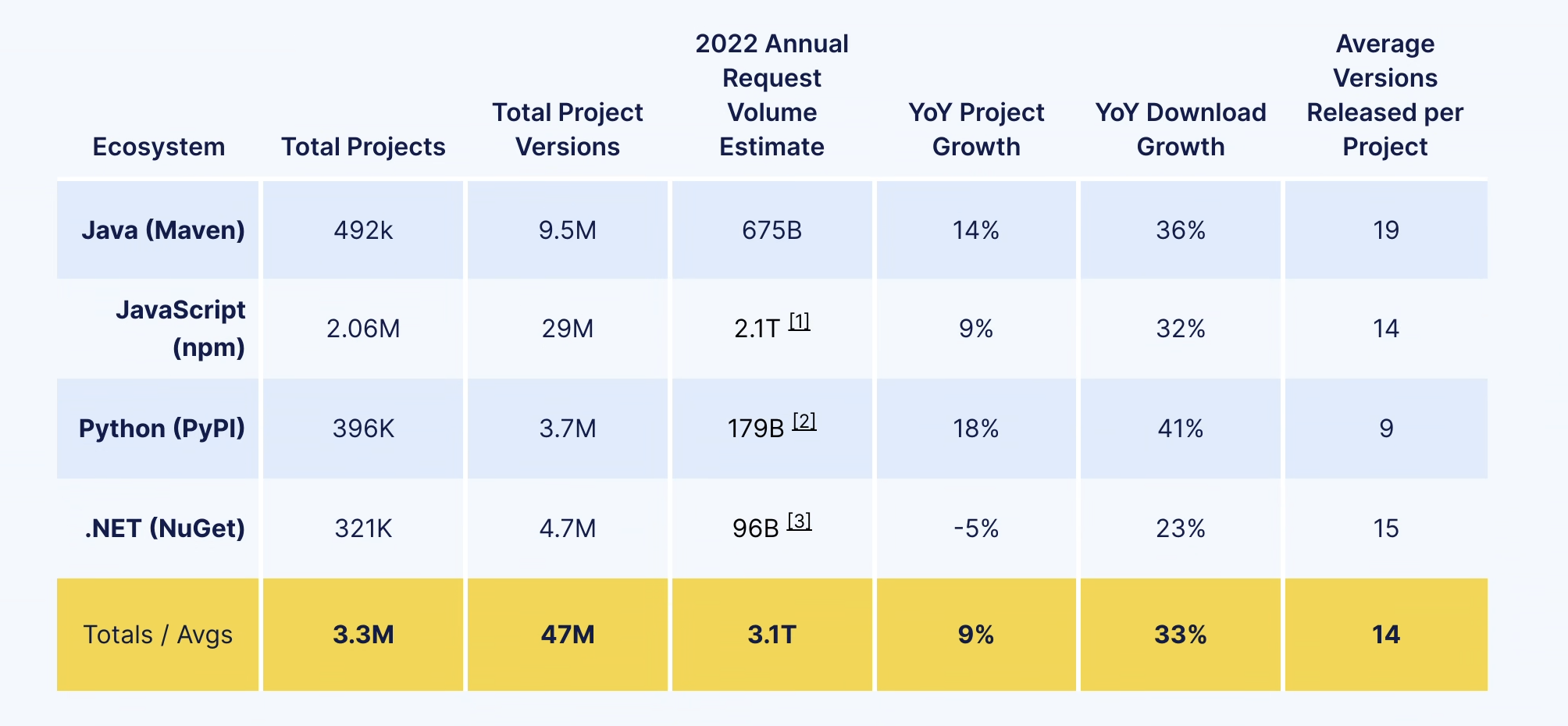
Economies and corporations all over the world digitizing with unabated increases combined with innovations in AI, cloud computing, cyber security, and the phenomena of remote work could be attributed to the significant increase in downloaded open source dependencies.
# Explosion of a New Threat Surface
The amount of third-party code flowing through software supply chains occurs on a massive scale. Yet published code accrues technical debt over time, creating the potential for compounded security vulnerabilities, if not kept up to date. Attackers can then exploit these vulnerabilities by using them as entry points into their targets’ systems, which is where we get into supply chain attacks (define, link to post).
A report released recently showed an alarming 740% increase in supply chain attacks on Open Source software. This is on top of the 650% increase reported last year.
This situation has been greatly accelerated by recent trends such as microservices architecture, containerization and cloud computing — all of which have made it easier than ever before to distribute your application across multiple servers, networks or even continents. These technologies allow you to build highly scalable applications that can run anywhere; but they also make it much easier… more entry points, larger attack surface, constantly changing, humanely impossible to audit and track…
Its important to understand the technical origins of this problem.
# Implication of Reuse: the Problem of Super Dependency
The way we define the concept of super dependency is when a a piece of software that you own relies on another piece of software, created by someone else, for critical functionality. In some cases, this can be as simple as using a third party API to outsource a specific function (e.g. using Stripe for payment processing, or Sendgrid for email delivery). In other cases, it can be much more complicated and involve multiple layers of dependencies.
In case of software developement, most of the depenndence exists in form of open source libraries and packages to form the building blocks of applications. The most popular programming launguages today are compelmented with open source package ecosystems such as npm, Maven, RubyGems and PyPi to power their toolchains. This toolchain allows anyone to create and reuse existing components without reinventing the wheel. This has lowered the barrier for building great, functional and scalable software in a short period of time for developers everywhere.
The problem with this approach is that it creates dependencies between these components and exposes them to potential vulnerabilities in each other’s code bases (and there are often many) - resulting a in massive attack surface (define).
# OSS Dependency Model
Today, any developer can use a module authoered by someone else using something as simple as npm install calculator or pip install x. That’s how easy it is to add dependencies to your project. Finding dependencies is just as easy. If you want to add some calculator functionality to your application, just Google “calculator npm,” and you’ll see an npm package as the first result—one that you can then add to your project.
In context of software development, 3rd-party software used as a building block of your application is called a dependency. There’s a reason why these packages as termed “dependencies.” – your software is now dependent on these packages, and this means that you’ve given the package full control over your project. You might also have done your due diligence and looked into the packages, ensuring that they are actively maintained.
Within the open-source ecosystem, the number of packages has grown exponentially. By extension, the number of transitive dependencies in each library has skyrocketed. For every package that project imports, the number of packages that each package requires, and that each of those packages requires and so on, has vastly increased. You might see a handful of dependencies for your main products, but there is now a hidden tail of thousands of additional libraries that are required to make those dependencies function properly.
# How It Propogates, and Where It Becomes Problematic
But here’s where it gets tricky. Behind the scenes, the package maintainer can potentially add anything to the package code files, like a crypto miner. Now, it’s highly unlikely that the crypto miner will be added to the direct dependency you’ve added to your project, such as the calculator package. However, the calculator package could be further dependent on a number of packages which are invisible to you and could possibly contain anything.
6 out of every 7 project vulnerabilities come from transitive dependencies.. (Sonatype report)
The ethos of open source is built on “shared trust” between a global community of individuals, which creates a fertile environment whereby bad actors can prey upon good people with surprising ease.
So its important to examine the concept of transitive dependenices and its implicaitons.
# Transitive dependencies and implicit trust
Simply worded, a transitive dependency is a “dependency of a dependency” (aka indirect dependency). The idea of using dependencies is heavily integrated entire developer community as a whole, across ecosystems. Developers like using the path of least friction when building, and “Don’t Repeat Yourself” (DRY) is a popular principle in programming.

To be clear, there are absolute advantages to using 3rd-party packages, and this post is not in any way intended to scare you away from using them. In fact, it is highly encouraged by another popular saying: “Don’t roll your own crypto” meaning you shouldn’t try to write cryptographic algorithms from scratch. In this case, it’s a good idea to use a package that many people have worked on and perfected.
The problem, and what you need to be cautious about, is that of implicit trust. When you import a package, you are not only implicitly trusting the people and contents of it, but all of the packages that it’s dependent on (aka transitive dependencies).
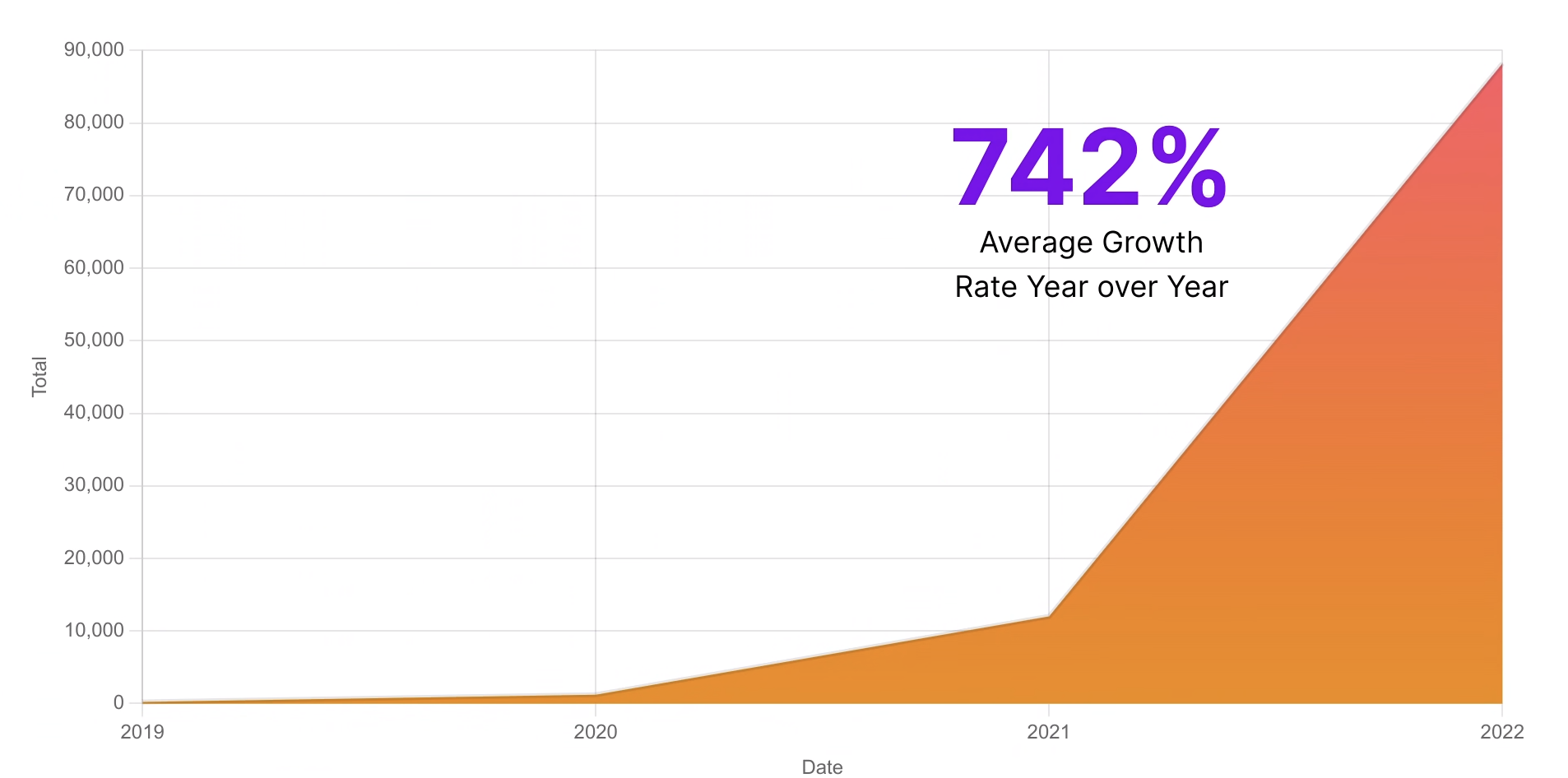
The super-dependent nature of modern software brings complexity. Because popular open source packages are often used directly or indirectly by a significant portion of the packages within an ecosystem, any vulnerability in such a package can have a massive impact across an entire ecosystem. It is found that an average JS project has 683 transitive dependencies, and these account for 75% of all vulnerabilties reported in npm advisories.
In general, the growth of transitive dependencies has been exponential since 2012, as shown in a study in 2019:

# Super dependency results in invisbility and loss of control
A whole set of hidden costs come bundled into upstream open source packages and libraries. Taking the example from earlier, say that you look through the README of the calculator package and add it by running npm install calculator. You implement the functionality into your application, and everything is working great. At this point, a few questions come to mind:
What do you actually know about the package? Have you gone through the code itself? Or the code files of its dependencies? Do you know who the maintainer is? Or who are the maintainers of its dependencies? Do you even know whether there are just one or multiple maintainers? How long has the package existed? Are you likely to get important updates and bug fixes in the future? These questions naturally result into further questions around security – what if any of those dependencies contained a critical vulnerability or malware?
Just to put this phenomenon in context: when installing an application on our smartphone from Google’s Play Store or iOS App Store, we’re used to knowing what actions the app will perform, what permissions we’re granting them, and how it will behave. Specifying this information is mandatory for any publisher. Then how can we get by without knowing what actions our dependencies will perform inside our software environments when we import them? After all, this is code written by someone else. How would you feel about an innocent-looking note-taking app accessing your contacts and location history? Probably not very comfortable.